本文介绍一致性hash算法的基本原理。他是swift中ring的理论基础,在下一blog中,会进一步介绍它在swift中的应用。
普通Hash算法
假设有四台存储节点(Drive 0, 1, 2 and 3),有4个object需要存储在上面。用普通的Hash算法实现方法如下:
- Step 1: 对象名称account/container/object作为键,使用MD5散列算法得到一个散列值key,
- step 2: 用第一步计算得到的key mod N 得到存储节点的号(0,1,2 and 3)
N:为存储节点的数量,本例中N=4.
存储节点和object的映射关系:
| OBJECT | HASH VALUE (HEXADECIMAL) | MAPPING VALUE | DRIVE MAPPED TO |
|---|---|---|---|
| Image 1 | b5e7d988cfdb78bc3be1a9c221a8f744 | hash(Image 1) % 4 = 2 | Drive 2 |
| Image 2 | 943359f44dc87f6a16973c79827a038c | hash(Image 1) % 4 = 3 | Drive 3 |
| Music 1 | 4b46f1381a53605fc0f93a93d55bf8be | hash(Image 1) % 4 = 1 | Drive 1 |
| Music 2 | 508259dfec6b1544f4ad6e4d52964f59 | hash(Image 1) % 4 = 0 | Drive 0 |
普通hash算法的缺点是: 如果N增加1,映射关系变成了key mod (N+1),会导致整个哈希环的重新分配,几乎全部的数据都要重新移动一遍,这样会造成极大的性能开销。
一致性哈希算法
一致性哈希算法实现
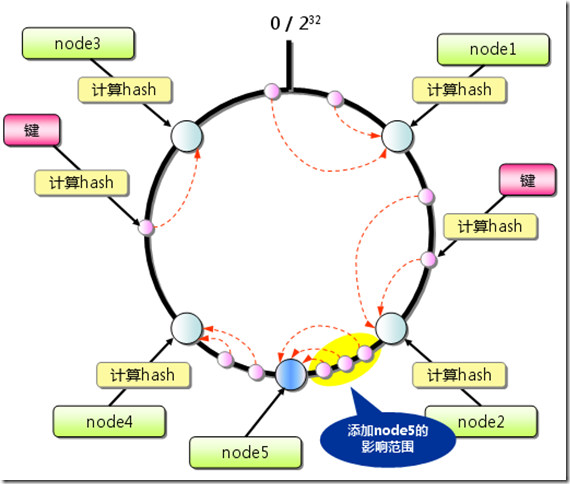
- Step 1: 每个节点的机器名或者是IP地址最键,使用MD5散列算法得到一个散列值key,并将其分配到一个圆环区间上(这里取0-2^32)。
- Step 2: 每个对象名称account/container/object作为键,使用MD5散列算法得到一个散列值key,也将其分配到这个圆环上。
-
Step 3: 从对象映射到的位置开始顺时针查找,将对象保存到找到的第一个节点上。
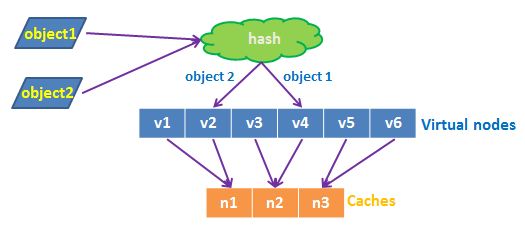
虚拟节点
平衡性是hash算法的一个重要指标,平衡性是指对于存储的所有对象,尽可能均匀的分到所有的设备上去。
注: 虚拟节点在swift里叫partion。
用上面提到的一致性哈希算法存储对象,当节点数量比较少时,平衡性会很差,所以引入了虚拟节点的概念来解决这个问题。
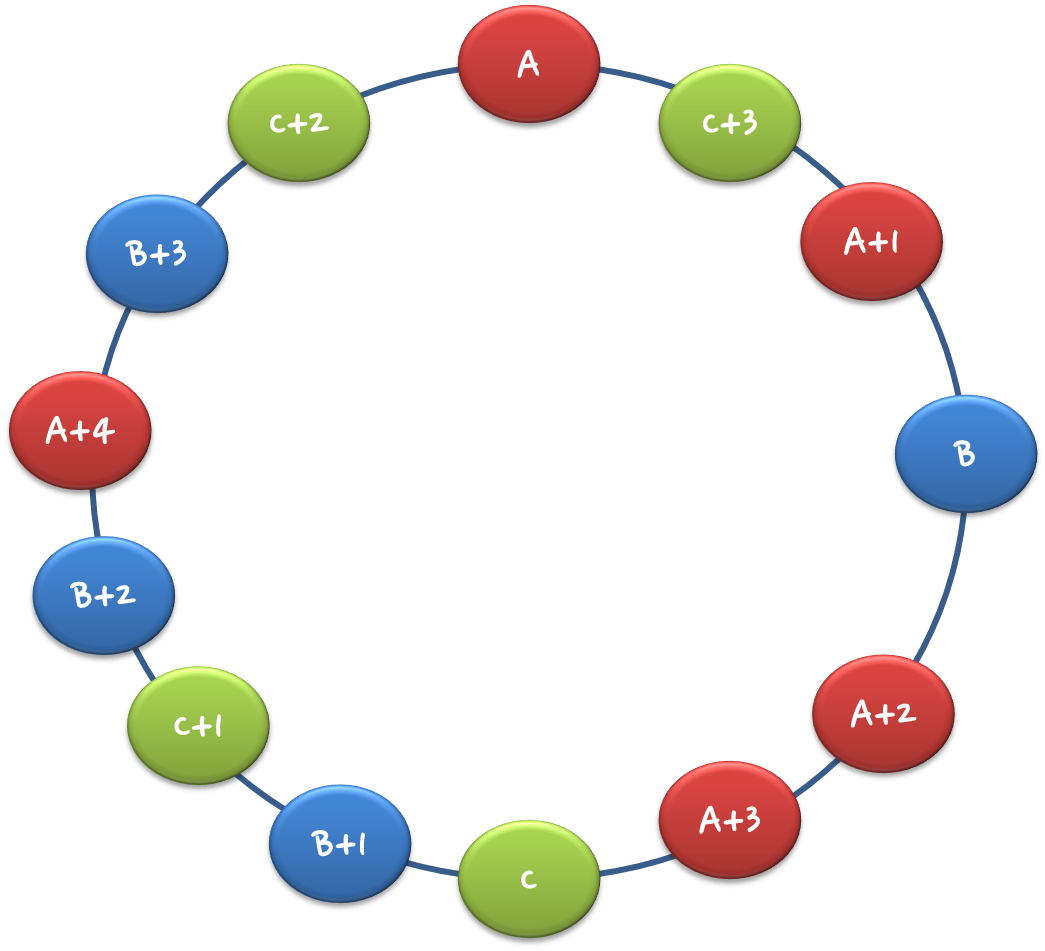
对每一个存储节点计算多个哈希,每个计算结果,都在ring中放置一个存储节点,称为虚拟节点。那么多个hash值该如何计算呢?在服务器ip或主机名的后面增加编号,然后
在计算Hash。比如一个存储节点对应三个虚拟节点,总共三个存储节点,计算方法如下:
-
Step 1: 分别以“A#1”、“A#2”、“A#3”做键,用MD5散列算法计算其散列值key,并将其分配到一个圆环区间上。
-
Step 2: 分别以“B#1”、“B#2”、“B#3”做键,用MD5散列算法计算其散列值key,并将其分配到一个圆环区间上。
-
Step 3: 分别以“C#1”、“C#2”、“C#3”做键,用MD5散列算法计算其散列值key,并将其分配到一个圆环区间上。
-
Step 4: 每个对象名称account/container/object作为键,使用MD5散列算法得到一个散列值key,也将其分配到这个圆环上。
-
Step 5: 从对象映射到的位置开始顺时针查找,将对象保存到找到的第一个节点上。
对象和存储节点的映射
加入虚拟节点后,一个实际的存储节点对应若干个虚拟的节点,对象和实际的存储节点的映射关系如下:对象——虚拟节点——设备,如下图所示: