本文介绍Swift 中ring的作用,ring的数据结构和ring中的核心概念。理解了ring,可以这么说,你对swift就理解了一半了。
Ring的作用
Swift文档中关于ring的描述:
-
ring用来确定数据驻留在集群中的位置。Account、container和单个object都有自己的ring。
-
ring中的每个partition在集群中默认有3个replica。
如果数据在整个集群中只有一份,一旦发生故障就可能会造成数据的永久性丢失。因此,需要有冗余的副本来保证数据安全
- ring使用zone的概念来保证数据的隔离。每个partition的replica都确保放在了不同的zone中。
一个zone可以是一个硬盘,一个服务器,一个机架,一个交换机,甚至是一个数据中心
Ring的数据结构
Swift的3个ring都包含下面3个元素:
设备列表
这个表用来定义集群中有多少个设备,如下所示:
[{'device': 'sdb1','id': 0,'ip': '127.0.0.1','meta': '','port': 6010,'weight': 1.0,'zone': 1},
{'device': 'sdb2','id': 1,'ip': '127.0.0.1','meta': '','port': 6020,'weight': 1.0,'zone': 2},]
表中关键概念的解释:
- Zone
- 引入zone的目的是为了让swift集群满足CAP理论的分区容忍性(Partition Tolerance)。
- 所谓的分区容忍性指:节点crash或者网络分片都不应该导致一个分布式系统停止服务
- 如果swift集群中的node都在一个机架上,一旦发生断电,网络故障,那么将不满足分区容忍性。因此就需要一种机制对机器的物理位置进行隔离。所以引入了zone的概念
- weight
- weight的目的是使数据在集群里均匀分布
- 实现方法是给容量大的节点分配更多的partition。例如,2T容量的node的partition数为1T的两倍
- 一个node的partition越多,在存储数据时,他就会有越多被选择的机会
Device 查询表
这个表里记录了replicas, partitions 和 devices的对应关系。Swift proxy通过这个表来查询对象存储在那个device上面。 举例:对于有3 replicas, 8 partitions 和 4 devices 的表如下:
r
e | +-----------------+
p | 0 | 0 1 2 3 0 1 2 3 |
l | 1 | 1 2 3 0 1 2 3 0 |
i | 2 | 2 3 0 1 2 3 0 1 |
c v +-----------------+
a 0 1 2 3 4 5 6 7
------------------>
partition
- 上面三个表有3行,每一行代表一个replica;有8列,每一列对应一个partition。表里面的0,1,2和3代表4个device。
- 当swift client通过GET请求去下载一个对象时,swift首先会计算这个对象的散列值,得到对应的partition,通过partition在Device查询表就可以定位存储对象的device。
Partition右移值 (Partition Shift Value)
这是个整数值决定对对象的散列值右移多少位,从而决定分区索引号partition。
object最终会存储在一个文件系统的目录里,目录的构成如下图所示:
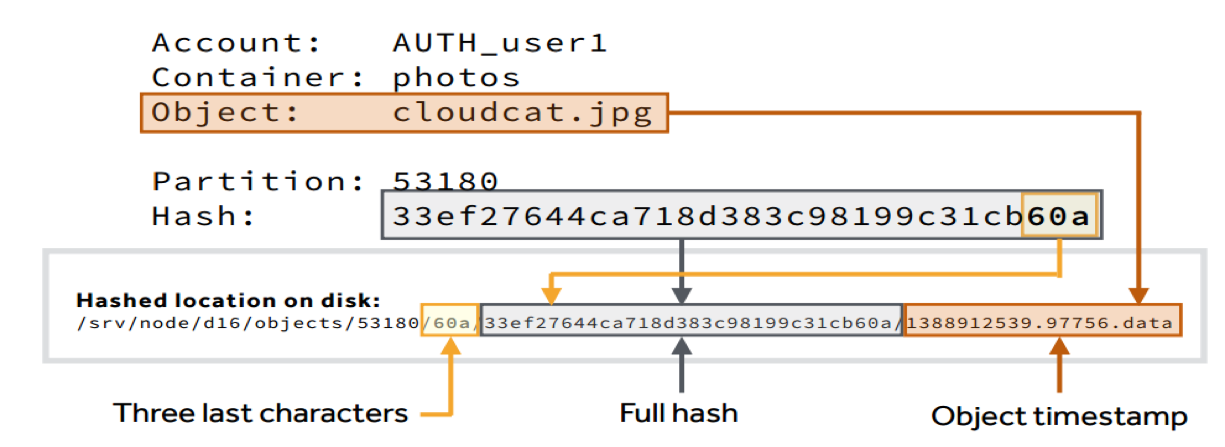
- 对象名称 account/container/object 作为键,使用 MD5 散列算法得到一个散列值
- 对该散列值的前 4 个字节进行右移操作得到分区索引号partition
由上图可见,对象的存储目录构成:分区索引号object/partition/散列值的后三位/散列值/时间戳
创建Ring
Swift services 不能改变Ring. Ring通过swift-ring-builder脚本管理 . 创建Ring时,需要指定下面几个参数:
- builder file
- partition power(or partition shift value)
- 每个partition的replicas数量
- 当一个partition被移动之后冻住不能再次移动的时长(小时)
partition会因为一些原因移动,实际是partition上的数据移动。为了避免网络拥塞,partition不会频繁的移动。默认最小移动间隔为一小时。
#swift-ring-builder <builder_file> create <part_power> <replicas> <min_part_hours>